
If you ask three people to describe DevOps, you’ll get four different answers. Sometimes, developers doing operations work is branded as DevOps. Others say it’s about the automation of infrastructure and deployments. Occasionally, you can see that DevOps is a modern title for sysadmins. We can see that the term has a buzzword status. So what’s the truth then? What is DevOps? In this post, I’ll try to shed some light on the meaning by summarizing the three core principles of DevOps—the three ways—according to The DevOps Handbook.
1. Principles of Flow
The First Way of DevOps is about creating a smooth flow of work through the different functional areas in an organization, from gathering requirements to operating software in production. Emphasis is put on the global goals of the entire system, not on the local objectives of individual departments. To make the concept more clear, let’s have a look at a couple of key takeaways.
1.1 Reduce Batch Size
Work-in-progress (WIP) is the amount of work that has been started but is not yet completed. A high amount of WIP is a sign of multitasking and can hinder the flow of work. To constrain WIP, we should reduce batch sizes. The idea originates from Lean Manufacturing. It was common in manufacturing to produce components in large batches. Setting up new machinery and switching between jobs was costly and time-consuming. Therefore, it was considered practical to create as many parts as possible once machinery had been set up.
For example, a car production plant would produce a lot of body panels to reduce the number of changeovers. This, however, creates a large amount of WIP. The variability in the flow of work cascades through the entire manufacturing plant, resulting in longer lead times. Imagine what would happen if a flaw was found in the body panels when a car was being assembled? Most likely, the entire batch has to be discarded and reproduced. Producing large batches delays feedback, and in case of errors, more work has to be redone.

The same ideas apply to software development. However, instead of machinery and body panels, we’re dealing with code. Every commit into version control increases the batch size in the software development value stream.
The batch size is the unit at which work-products move between stages in a development process.
A classic example is an annual production deployment schedule. If a deployment is done once a year, the batch size is enormous; a year’s worth being is deployed in a single step. Similarly to the car plant, if anything goes wrong, the entire batch has to be rolled back. Extra effort must then be put into redoing work that was considered done. And to add insult to injury, it’s challenging to find and fix the issues that caused the deployment to fail if introduced, say, 6 months ago.
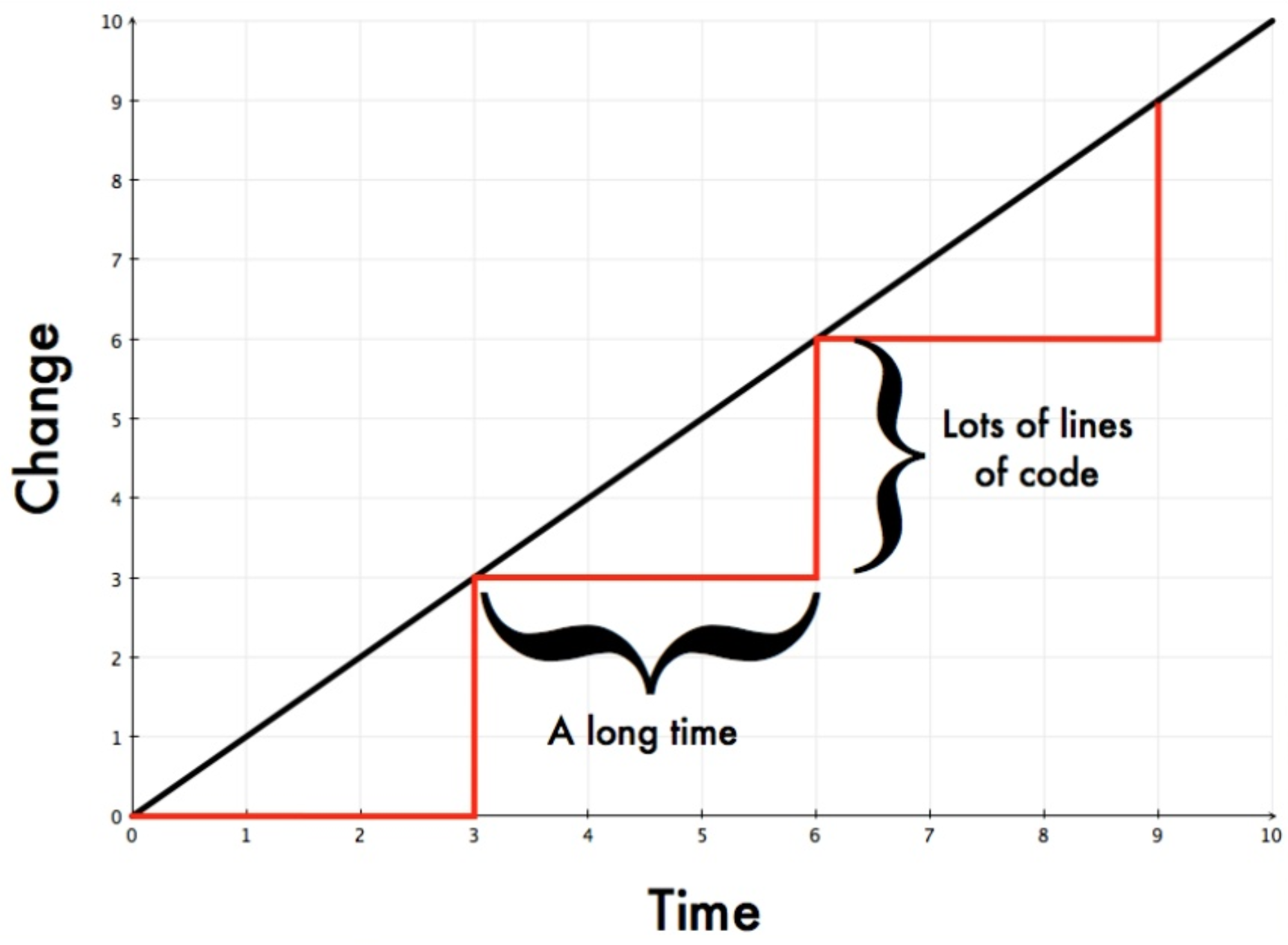
Similar issues can be seen when long-lived feature branches are used. The longer a branch stays isolated and the more changes it sees, the larger the batch size. Over time, it becomes increasingly difficult to integrate it back to the mainline. The potential for merge conflicts is high. Since feedback is delayed, the potential for rework is high. These factors are disruptive to the flow of work and increase deployment lead times.
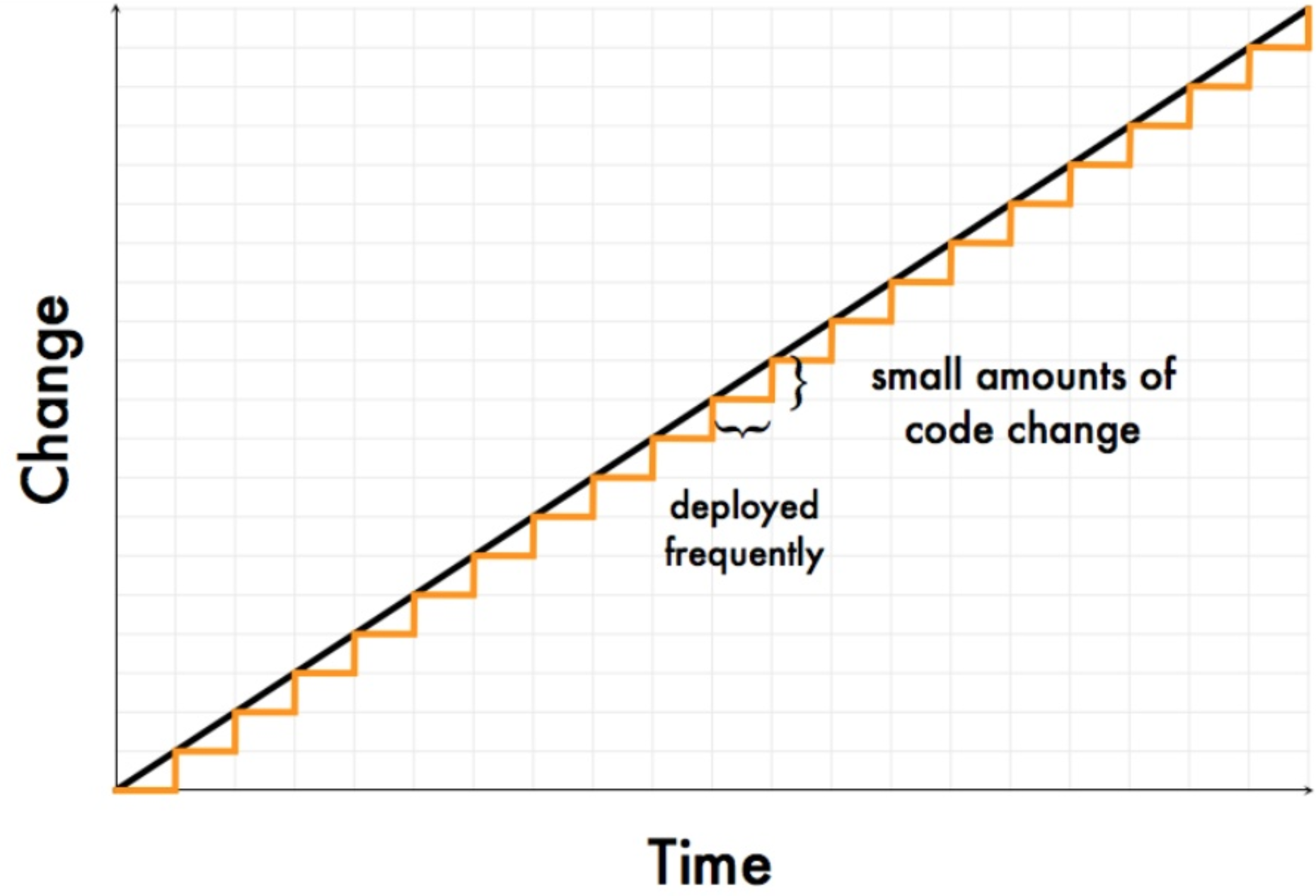
To improve deployment lead times, we have to make batch sizes smaller. Long-lived feature branches are discouraged. We can get faster feedback if we integrated early and often and deployed software in smaller increments. If we continue to reduce the batch size, we eventually arrive at a single piece flow, where every commit flows through the entire software development value stream. Once all automated checks have passed, changes end up in production.
Teams that can pull that off make use of practices such as trunk-based development, continuous integration, continuous delivery, and continuous deployment. They’ve invested in test automation and have designed their software for low-risk releases. They’ve also organized themselves so that the number of required hand-offs is minimized. Hand-offs require communication and coordination. Unfortunately, even under the best circumstances, some knowledge gets lost. This is a potential spot where errors can creep in, and work can pile up, disrupting the flow and increasing deployment lead times.
1.2 Eliminate Constraints
Continually identifying and eliminating constraints in our work is the key to improving throughput and reducing lead times. In Beyond the Goal: Theory of Constraints, the author Dr. Goldratt states
In any value stream, there is always a direction of flow, and there is always one and only one constraint; any improvement not made at that constraint is an illusion.
An example from a technology value stream is environment creation. If it takes hours to set up a testing environment, any improvements we do to work that happens before it in a value stream is an illusion.
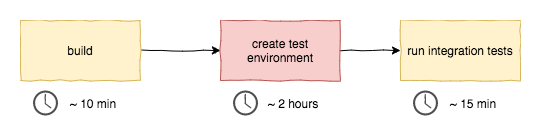
For instance, if we reduce our build time from 10 to 3 minutes, we get faster builds. But nothing gets done faster overall. Environment creation is still a blocker. What’s worse, WIP is increased. New builds pile up even more quickly now, waiting to be deployed to the test environment. Since environment creation blocks new work from passing through, steps that should happen after are starved of work. We should find the constraint in our value stream, eliminate it, and then find the next one.

2. Principles of Feedback
The second way of DevOps is about creating fast feedback loops that allow us to build safer systems. Whether you like it or not, software is complicated. Even the smallest of changes can have catastrophic consequences. Without fast feedback, we distance the cause and effect. Errors can slip in undetected, only to be discovered later when the cost and effort to fix them is higher.
2.1 Importance of Fast Feedback
Ideally, we’d like to see problems as they occur. If you’ve written any code in an IDE or a text editor that points out issues as you type them, then you know what I’m talking about. Ah, the red squiggly line. It’s easy to fix problems when they’re discovered shortly after they’ve been created. Additionally, we get to learn from them.
It is impossible for a developer to learn anything when someone yells at them for something they broke six months ago—that is why we need to provide feedback to everyone as quickly as possible, in minutes, not months
Unfortunately, we don’t have a red squiggly line in our editors for future production issues. Nor do we have them for unwanted or badly designed features. The next best thing is to reduce the time between when a problem is introduced and when it is detected.
In environments where quality is somebody else’s problem, we involuntarily delay feedback. For instance, if QA is exclusively in charge of the correctness of the work produced by developers or operations is solely responsible for the software in production, quality is moved further away from the source. Feedback is received by handing over work to the next work center in the value stream. Unfortunately, handovers create delays. Work can pile up because, say, QA is busy testing something else or operations doesn’t have time to provision a testing environment.
Without immediate feedback, we risk passing on defects to downstream work centers. Consequently, this can create disruptions in the flow of work. Not only are issues more difficult and time-consuming to fix when they’re detected later in a value stream, but we also run the risk of increasing work-in-progress. For example, if QA is available to test your work starting from, say, tomorrow, you’re not going to wait for them to finish. Instead, you’re going to work on something else. However, if any issues are found, you’re going to have to multitask between old and new work. Fast feedback, on the other hand, prevents the start of new work and gets us closer to the single-piece flow.
2.2 Push Quality Closer To The Source
It seems counterintuitive, but adding more inspection steps and approval processes increase the likelihood of failures. Surely, having more eyes on the problem should produce better results, right? That might be true if everybody is fully informed of the work at hand. But as we start to push decision-making further from where the work is performed, the effectiveness of approval processes decreases.
Getting approvals from people who are distant from the work has several issues. First of all, they don’t have the most up-to-date information. Secondly, they might be busy with other work. Approvals can start to pile up, creating delays. Under time pressure, decisions can be rubber-stamped. These quality control measures give you a false sense of security. To receive faster and more useful feedback, we should instead push quality closer to the source.

Quality shouldn’t be exclusively QA’s responsibility. Everybody should find and fix issues in their area of control. In technology value streams, fast feedback close to the source can be achieved with, for example, build automation, automated testing, automated security and vulnerability checking, automated deploys, production telemetry, and alerting. Automation helps us quickly detect problems, recover from them, and learn how to prevent them.
In addition to end-users, we should have empathy for our internal customers. Designing software with testability in mind makes the job of QA more effective. It shouldn’t be the responsibility of operations to figure out how to configure, deploy, and monitor the software. And we shouldn’t forget the goals of information security, sales, and marketing. By thinking about these concerns early on, we create quality closer to the source.
3. Principles of Continual Learning
The third way is about creating a culture of continual learning and experimentation. Fast feedback enables us to learn from our mistakes. But that’s only part of the solution. We want to continually improve, experiment, and create new knowledge in the entire organization. After all, organizations that can learn quicker than others have a competitive advantage.
3.1. High-trust Culture
In low trust work environments, incidents are often followed by the name, shame, blame pattern. This, however, obstructs individuals and the entire organization from learning. Getting punished for mistakes incentivizes you to stay in your comfort zone; that happy little place where you’re less likely to cause problems. You’re discouraged from experimenting, trying out new things, and asking “what-if” questions. Instead of taking responsibility, it’s more convenient to hide failures under the covers. People are less likely to speak up and propose novel solutions to existing problems. Those who try to innovate are met with resistance.
When small failure signals are continually withheld, they accumulate, until a major catastrophe happens. The immediate response from management is to add extra processes and approvals to avoid a future disaster. This results in lower throughput and longer lead times but doesn’t solve the underlying problem.
Ron Westrum, in his 2004 paper titled “A Typology of Organisational Cultures”, describes this as having a pathological organization culture.
When things go wrong, pathological climates encourage finding a scapegoat […] Pathological environments will discourage taking responsibility, and can be expected to conceal their problems.
Westrum defines three dominant types of organization culture—pathological, bureaucratic, and generative. On the opposite side to pathological, we have generative organizations.
Generative organisations require empowerment for maximum performance. Individuals’ minds are harnessed to fulfill the organisation’s goals through a culture of conscious inquiry. They are encouraged to speak up, think outside the box, and to act as fully conscious participants in a great cooperative enterprise.
The 2014 State of DevOps Report goes on to say that in generative environments, it is understood that continuous improvement leads to ever-higher levels of throughput and stability. Learning is actively promoted. Everybody is encouraged to run experiments to learn how to improve both processes and the products and services they build. Instead of blaming humans for errors, they look into ways to redesign the system to prevent another one. And when failures do happen, they’re treated as learning opportunities. When faced with incidents, blameless post-mortems are held. Results are shared with the entire organization to transform local discoveries into global improvements.
By removing blame, you remove fear; by removing fear, you enable honesty; and honesty enables prevention
3.2. Continuous Improvement
Teams that are too busy to improve their daily work, and regularly rely on workarounds, increase their technical debt. Not only will they continue to suffer, but the suffering increases over time. Processes degrade, productivity plummets, and throughput decreases.
Are you too busy to improve pic.twitter.com/O9Gmel3ICB
— Shayne 👨🏿💻 UXD (@shaynecuffy) August 13, 2014
Improvement shouldn’t be viewed as an optional activity, something you do when you have extra time. It should be continuous, part of the daily routine of every team. Time should be consciously reserved to pay down technical debt, run experiments, improve workflows, and create new knowledge. In a continuous improvement culture, improving the way we work is more important than doing the work!
Summary
The DevOps Handbook lays out three core principles. In short, they are:
- Smooth flow of work from development to operations to customers
- Amplification of feedback loops so that corrections and improvements can be continuously made
- Creation of a high-trust culture that encourages experimentation and learning from failure
This post covered what I found most valuable. But the book goes into more detail about various practices that go along with the principles. It is a recommended read for everyone interested in DevOps.